问题1:如果是先修改数据库,再删除缓存,如果删除缓存失败,那么会导致数据库中的数据是新数据,缓存中的是旧数据
,数据不一致。
解决思路:先删除缓存,再修改数据库,如果删除缓存成功了,修改数据库失败了,那么数据库中是旧数据,缓存中是空的,那么数据不会不一致,因为读的时候缓存没有,则读数据库中旧数据,然后更新到缓存中
Cache Aside Pattern
读的时候,先读缓存,缓存没有的话,那么就读数据库,然后取出数据后放入缓存,同时返回响应
更新的时候,先操作数据库,再删除缓存
1.如果先删除缓存,可能因为并发太大,数据库还没更新老的数据又被另外一个查询放入了缓存,这时候缓存是老数据,数据库是新数据。数据不一致。
2.但是如果先操作数据库,后删除缓存,如果删除缓存失败。缓存是老数据,数据库是新数据,但是删除缓存失败的概率比上面并发造成数据不一致的概率要小得多。但是具体还是要结合场景来考虑
为什么是删除缓存,而不是更新缓存
1,因为很多时候缓存不是直接数据库直接取出来的值,很可能做了逻辑运算以后再存入数据库
如果这类的数据要更新,则需要将相关的数据都查出来再去计算更新,这样代价太高了。
2,如果你频繁修改一个缓存涉及的多个表,那么这个缓存会被频繁的更新,频繁的更新缓存,但是问题在于,这个缓存到底会不会被频繁访问到?
1 | 举个例子,一个缓存涉及的表的字段,在 1 分钟内就修改了 20 次,或者是 100 次,那么缓存更新 20 次,100 次; 但是这个缓存在 1 分钟内就被读取了 1 次,有大量的冷数据 |
其实删除缓存,而不是更新缓存,就是一个 lazy 计算的思想,不要每次都重新做复杂的计算,不管它会不会用到,而是让它到需要被使用的时候再重新计算
mybatis、hibernate 就是懒加载思想
问题2:一个比较复杂的数据不一致问题
1,数据发生了变更,先删除缓存,然后要去修改数据库,此时还没修改
2,一个并发请求过来,去读缓存,发现缓存空了,然后去查询数据库,查到了修改前的值,放到缓存
这时候出现数据库和缓存不一致。
解决思路: 导致这种情况出现的原因是读写并发请求造成的,根据某个规则比如商品 ID 相同的请求路由到一台服务器上,可以尝试将读请求和更新请求进行串行化处理,
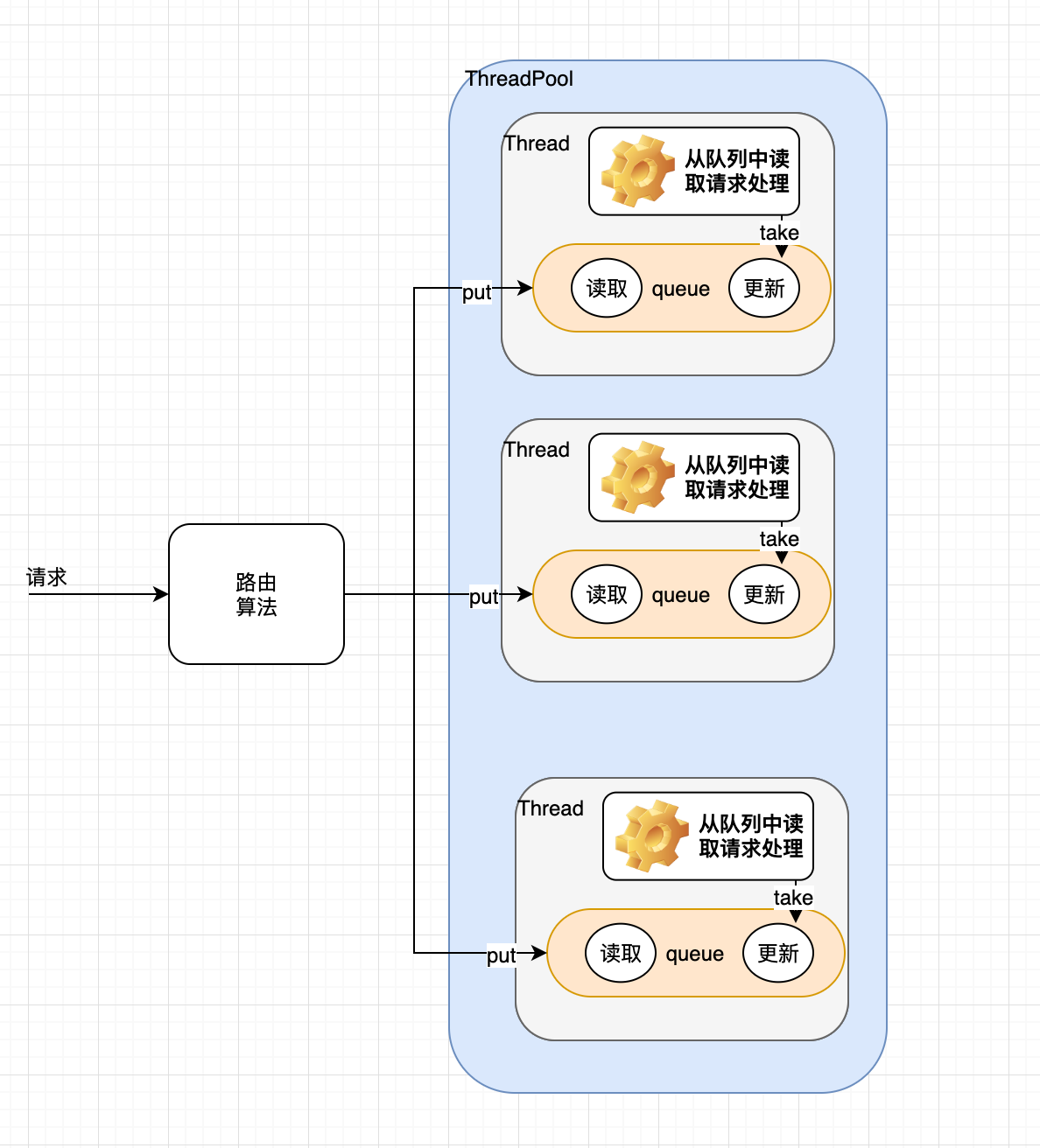
具体流程如下:
- 更新数据的时候,根据数据的唯一标识,将操作路由之后,发送到一个 jvm 内部的队列中
- 读取数据的时候,如果发现数据不在缓存中,那么将重新读取数据 + 更新缓存的操作,根据唯一标识路由之后,也发送同一个 jvm 内部的队列中
- 一个队列对应一个工作线程,每个工作线程串行拿到对应的操作,然后一条一条的执行
这样的话,一个数据变更的操作,先执行,删除缓存,然后再去更新数据库,但是还没完成更新
此时如果一个读请求过来,读到了空的缓存,那么可以先将缓存更新的请求发送到队列中,此时会在队列中积压,然后同步等待缓存更新完成
待那个队列对应的工作线程完成了上一个操作的数据库的修改之后,才会去执行下一个操作,也就是缓存更新的操作,此时会从数据库中读取最新的值,然后写入缓存中
如果请求还在等待时间范围内,不断轮询发现可以取到值了,那么就直接返回;
如果请求等待的时间超过一定时长,那么这一次直接从数据库中读取当前的旧值
需要优化的点
1,一个队列中已经存在一个更新操作 + 一个读取操作,则后续的读请求可以尝试等待一段时间从缓存读取,因为前面的更新会删除缓存,后面的读取请求会将
再次放入到缓存中,后续的读请求可以尝试等待一段时间从缓存读取,如果等待时间过了再尝试从数据库去拿
此方案的风险点
1,可能 数据更新很频繁,导致队列中积压了大量更新操作在里面,然后读请求会发生大量的超时,最后导致大量的请求直接走数据库。所以务必通过一些模拟真实的测试,看看更新数据的频繁是怎样的
2,因为一个队列中,可能会积压针对多个数据项的更新操作,因此需要根据自己的业务情况进行测试,可能需要部署多个服务,每个服务分摊一些数据的更新操作
3, 会存在热点数据都打到同一台机器上的,可能造成某台机器压力过大的问题。