实现一个短连接服务
| 所用技术 | 功能 | 完成度 |
|---|---|---|
| Spring Boot | 框架 | 已完成 |
| MySQL | 数据存储 | 已完成 |
| Redis | 二级缓存 | X |
| OpenResty | 代理 + 一级缓存 | 已完成 |
| EhCache | 三级缓存 | 已完成 |
| 布隆过滤器 | 判断hash是否存在 | 已完成 |
简介
- 短链接好处
- 短链跳转的原理
- 锻炼生成的几种方式
短链接好处

为啥要使用短链接
- 大家可能都收到过这样的推广短信,点击上面链接后会跳转到指定的地址,大家有没想过别后的实现细节
- 我们经常需要将链接转成二维码的形式分享给他人,如果是长链的话二维码密集难识别,短链就不存在这个问题了,如图示
- 链接太长在有些平台上无法自动识别为超链接
1 |
|
大家可能都收到过这样的推广短信,点击上面链接后会跳转到指定的地址,大家有没想过背后的实现细节
短链跳转的原理
我们可以从这些短链接请求看下原理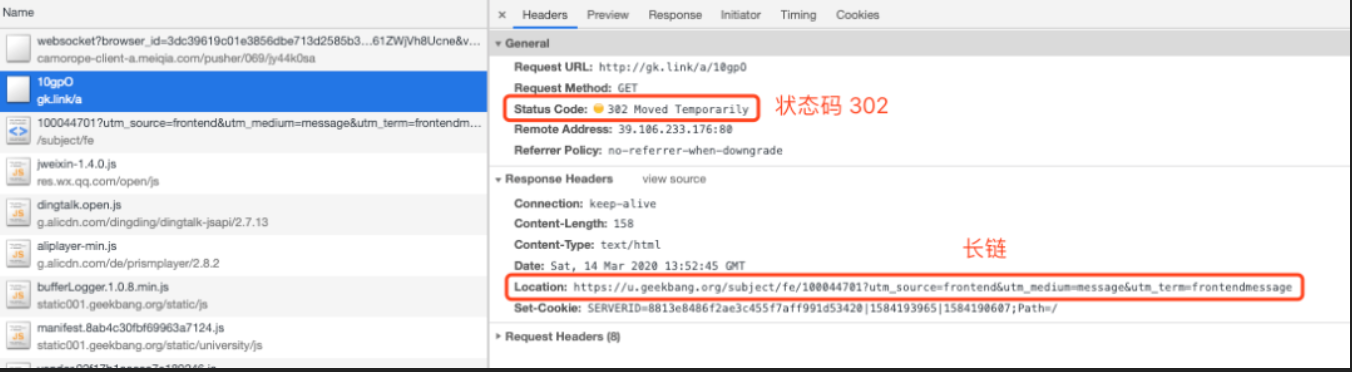
我们可以看到请求的http状态码是 302(重定向) 和 Location值具体跳转目标地址,浏览器拿到了得到这个长链接,发起重定向请求到目标地址
整体交互流程如下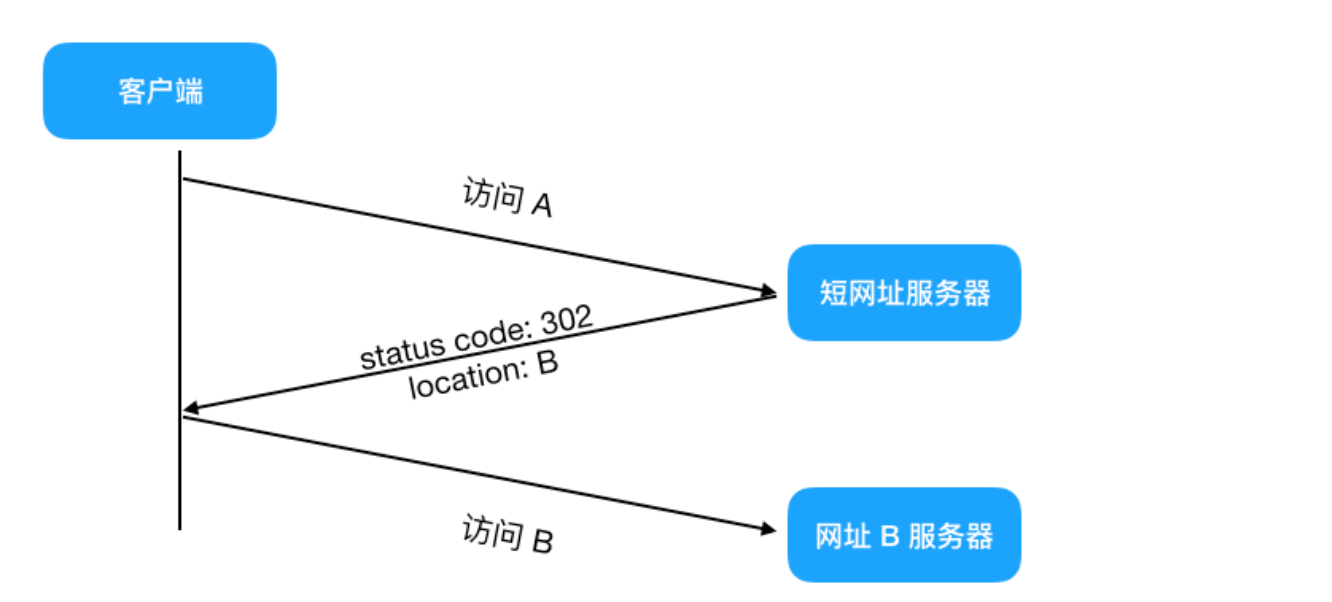
这里有个问题http状态码, 301和302 有什么区别
- 301: 代表 永久重定向,也就是说第一次请求拿到长链接后,下次浏览器再去请求短链的话,不会向短网址服务器请求了,而是直接从浏览器的缓存里拿,这样在 server 层面就无法获取到短网址的点击数了,如果这个链接刚好是某个活动的链接,也就无法分析此活动的效果。所以我们一般不采用 301
- 302: 代表 临时重定向,也就是说每次去请求短链都会去请求短网址服务器(除非响应中用 Cache-Control 或 Expired 暗示浏览器缓存),这样就便于 server 统计点击数,所以虽然用 302 会给 server 增加一点压力,但在数据异常重要的今天,这点代码是值得的,所以推荐使用 302
短链接生成的几种方式
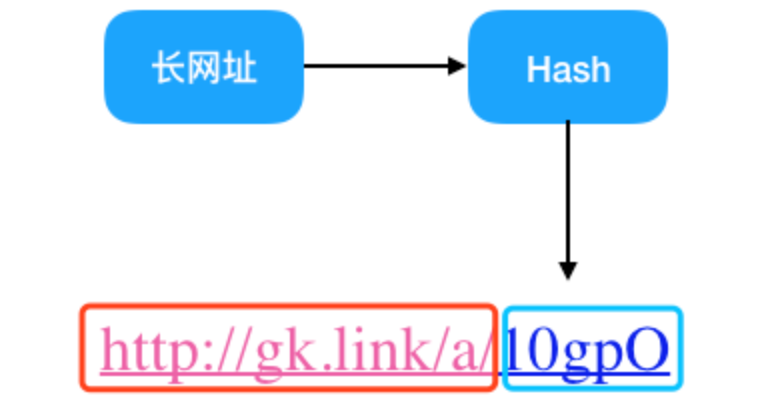
通过观察发现上面提到的短链接能发现,它是由固定的短链接域名 + 长链接映射成的一串字母组成,那么长链接怎么才能映射成一串字母呢?
哈希算法
哈希算法非常多,我们如何选择呢? 很多人可能会想到MD5, SHA等算法,但是我们选择 hash 算法的时候需要考虑的,生成的性能,
和产生冲突的概率。我们不回去考虑反向解码的性能或者难度,因为我们之直接将生成的 hash 字符串和长链接映射,不需反向生成。
我们项目中使用Google 出品的 MurmurHash 算法,MurmurHash 是一种非加密型哈希函数,适用于一般的哈希检索操作。与其它流行的哈希函数相比,对于规律性较强的 key,MurmurHash 的随机分布特征表现更良好
非加密意味着着相比 MD5,SHA 这些函数它的性能肯定更高(实际上性能是 MD5 等加密算法的十倍以上),也正是由于它的这些优点,所以虽然它出现于 2008,但目前已经广泛应用到 Redis、MemCache、Cassandra、HBase、Lucene 等众多著名的软件中
MurmurHash 提供了两种长度的哈希值,32 bit,128 bit,为了让网址尽可通地短,我们选择 32 bit 的哈希值,32 bit 能表示的最大值近 43 亿,对于中小型公司的业务而言绰绰有余。
对长链(https://yefan813.github.io/)做 MurmurHash 计算,得到的哈希值为 849756688,于是我们现在得到的短链为 固定短链域名+哈希值 = http://xxxx.cn/849756688
1.如何让短网址更短?
不过,你可能已经看出来了,通过 MurmurHash 算法得到的短网址还是很长啊,而且跟我们开头那个网址的格式好像也不一样。别着急,我们只需要稍微改变一个哈希值的表示方法,就可以轻松把短网址变得更短些。
我们可以将 10 进制的哈希值,转化成更高进制的哈希值,这样哈希值就变短了。我们知道,16 进制中,我们用 A~E,来表示 10~15。在网址 URL 中,常用的合法字符有 0~9、a~z、A~Z 这样 62 个字符。为了让哈希值表示起来尽可能短,我们可以将 10 进制的哈希值转化成 62 进制。具体的计算过程,我写在这里了。最终用 62 进制表示的短网址就是

2.如何解决哈希冲突
解决思路,根据长链接生成hash字符串,然后去查找数据库会出现以下几种情况
- 数据库不存在:这时候直接插入字符串和对应的长链接即可。
- 数据库存在:对应的长链接一样,这时说明其他人已经将次长链接生成了对应的短链接,这时候直接返回即可。
- 数据库存在:对应的长链接不一样,则说明冲突了,此时可以将长链接尾部,拼接一串特殊字符,比如“[DUPLICATED]”,然后跟再重新计算哈希值,两次哈希计算都冲突的概率,显然是非常低的。假设出现非常极端的情况,又发生冲突了,我们可以再拼接字符串,再计算哈希值。然后把计算得到的哈希值,跟原始网址拼接了特殊字符串之后的文本,一并存储在 MySQL 数据库中
压测一下看看性能
其实这里没有做任何的缓存,所以请求全部落到数据库,很容易就能想到不能支持高并发,但还是压测一下装个 X
100线程 并发执行生成短链接接口

短链接跳转接口结果和上面差不多
短链接跳转需要查询数据库,这时候其实可以将查询到的数据放入到本地缓存(三级缓存)还可以放入到 redis(二级缓存) ,也可以放入到 Nginx(一级缓存)
加入本地缓存 Ehcache
服务使用 Ehcache 后,压测短链接跳转结果

加入 Redis 缓存
TODO
加入 OpenResty
TODO
3.如何优化哈希算法生成短连接的性能
TODO
利用 ID 生成器生成短链接
TODO
阶段一:实现一个简单的短连接服务
- 根据URL生成短连接
- 实现短连接的跳转
问题:
- 如何解决Hash冲突问题
- 如何支持高性能短连接结构设计,例如:如何支持大量的并发生成短连接请求
阶段二:实现一个高性能的短链接服务器
- 支持大并发访问生成短链接