Kafka存储结构详解
1 Topic
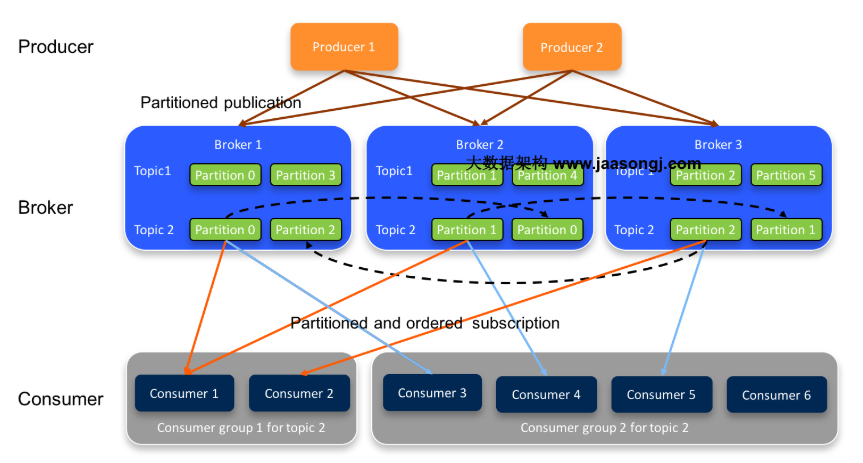
- 用一个Topic的消息可以分布在一个或者多个broker上
- 一个 Topic 包含一个或者多个 partation
- 每个消息都属于且仅属于一个Topic
- Producer 发布数据时,必须指定该消息发布到哪一个 Topic 上
- Consumer 订阅消息时,必须制定订阅哪个 Topic
2 Partition
- 物理概念,一个 partition 只分布在一个 broker 上(不考虑备份)
- 一个 partition 物理上对应一个文件夹
- 一个 partition 包含多个 segment(逻辑上的概念,不存在具体物理文件)
- 一个 segment 对应一个文件
- segment由一个个不变记录组成
- 记录只会被 append 到 segment,不会被单独修改或者删除
- 清除过期日志时,直接删除一个或者多个 segment

topic名称-分区数命名1
2
3
4//分布在不同的broker节点上
test-topic-0
test-topic-1
test-topic-2
partition文件存储方式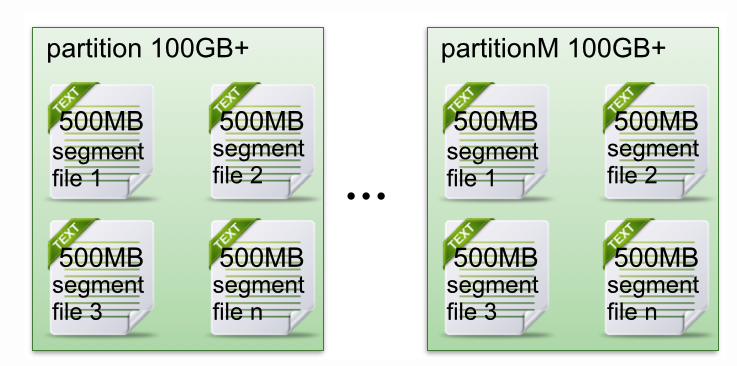
疑问: 为什么需要分区
为了性能考虑,如果不分区每个topic的消息只存在一个broker上,那么所有的消费者都是从这个broker上消费消息,那么单节点的broker成为性能的瓶颈,如果有分区的话生产者发过来的消息分别存储在各个broker不同的partition上,这样消费者可以并行的从不同的broker不同的partition上读消息,实现了水平扩展。
总结一句话:可以多个 broker 同事操作,提高并行度
2.2 分区文件下存了哪些东西

3 Segment
segment 是个逻辑上的概念,并不存在真实的 segment 文件
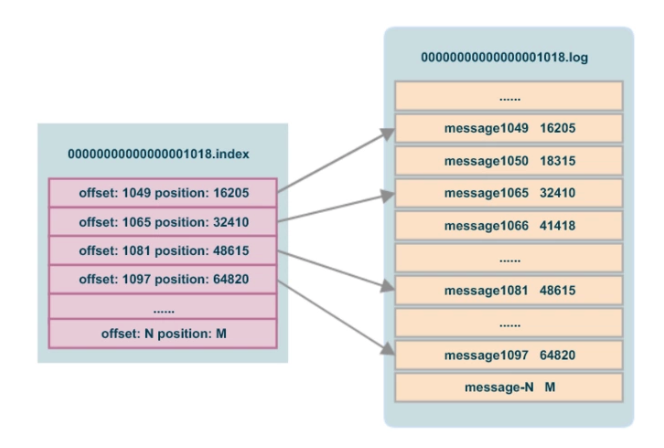
Segment 是由一个 .index 和 一个 .log文件组成的。所以从可看到一个上图一个 partition 存在一个或者多个 segment。
- .index 文件是索引文件用来快速的查找真实消息数据
- .log 文件是用来存储数据的文件
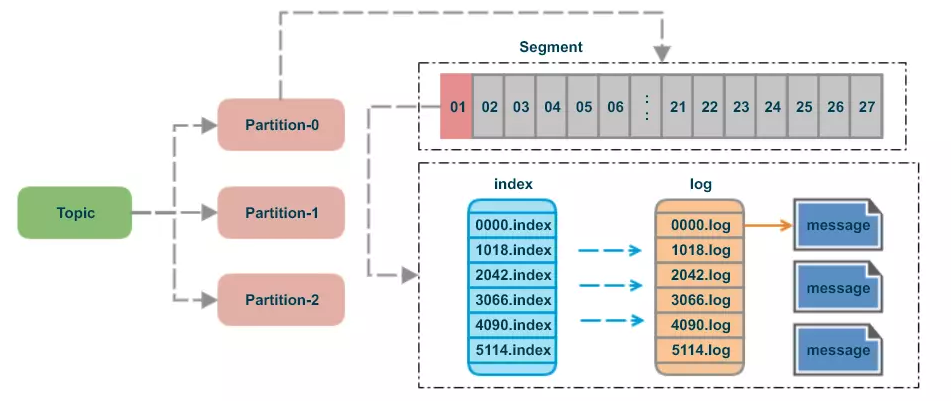

疑问: 为什么有了 Partition 还需要 segment
通过上面的图,可以了解到一个 partition 下存在多个 segment,一个 segment 由有一个.index和一个.log文件组成,如果不用这种方式,那可以使用一个.index和一个.log文件组成(类似RocketMQ中使用CommitLog文件来保存所有的数据文件,由多个 indexfile 来存储索引文件)。这样的坏处是,随着消息的不断写入这个文件,由于kafka的消息不会做更新操作都是顺序写入的,如果做消息清理的时候只能删除文件的前面部分删除,不符合kafka顺序写入的设计,如果多个segment的话那就比较方便了,直接删除整个文件即可保证了每个segment的顺序写入。
总结一句话:为了提高写入的效率,以及方便清除不需要的数据
3.1 .index文件内部存储了哪些数据
存储了对应数据文件的部分offset,以及 position(表示具体消息存储在log中的物理地址)。可以看待 offset 并不是连续的,而是每隔 6 个 offset 存储一条索引数据。1
2
3
4
5
6offset: 1049 position: 16205
offset: 1065 position: 32410
offset: 1081 position: 48615
offset: 1097 position: 64820
offset: 1113 position: 81025
offset: 1129 position: 97230
疑问: 为什么 index 文件中这些 offset 不是连续的编号呢?
因为index文件中并没有为数据文件中的每条消息都建立索引,而是采用了稀疏存储的方式,每隔一定字节的数据建立一条索引。这样避免了索引文件占用过多的空间,从而可以将索引文件保留在内存中。但缺点是没有建立索引的Message也不能一次定位到其在数据文件的位置,从而需要做一次顺序扫描,但是这次顺序扫描的范围就很小了。这种存储方式叫做稀疏索引
也可以配置成稠密索引,带来的问题就是索引文件太大。但是查找效率会高一点
总结一句话:减小 index 文件大小,可以将 index 文件内容加载到内存中,从而减小占用内存空间大小
3.2 .log文件存储了那些数据
log数据文件中并不是直接存储数据,而是通过许多的message组成,message包含了实际的消息数据。

4 消费者如何根据 offset 查找 message
假如我们想要读取offset=1066的message,需要通过下面2个步骤查找。
- 查找segment file
00000000000000000000.index表示最开始的文件,起始偏移量(offset)为0.第二个文件00000000000000001018.index的消息量起始偏移量为1019 = 1018 + 1.同样,第三个文件00000000000000002042.index的起始偏移量为2043=2042 + 1,其他后续文件依次类推,以起始偏移量命名并排序这些文件,只要根据offset 二分查找文件列表,就可以快速定位到具体文件。 当offset=1066时定位到00000000000000001018.index|log - 通过segment file查找message
通过第一步定位到segment file,当offset=1066时,依次定位到00000000000000001018.index的元数据物理位置和00000000000000001018.log的物理偏移地址,此时我们只能拿到1065的物理偏移地址,然后再通过00000000000000001018.log顺序查找直到offset=1066为止。每个message都有固定的格式很容易判断是否是下一条消息