1 RocketMQ消息存储结构
Broker 整体架构图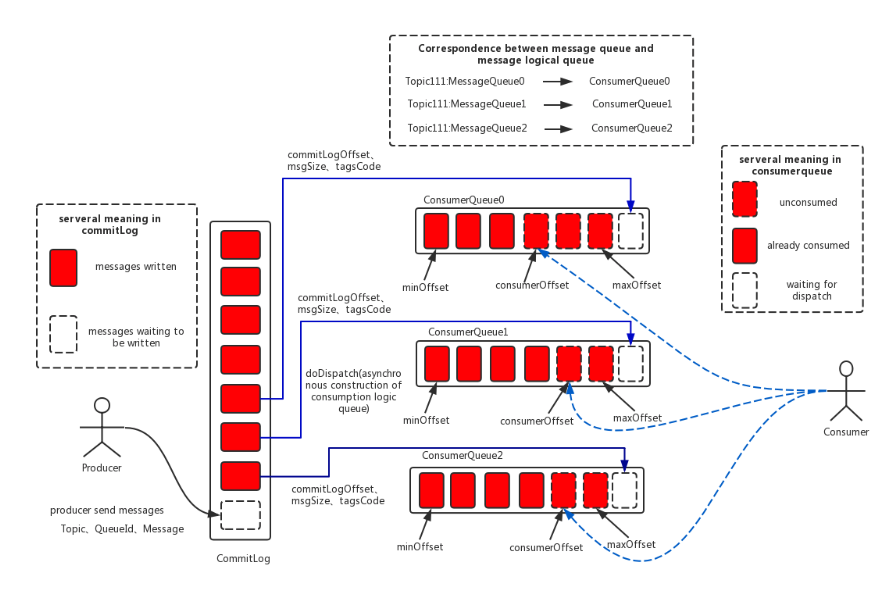
消息体结构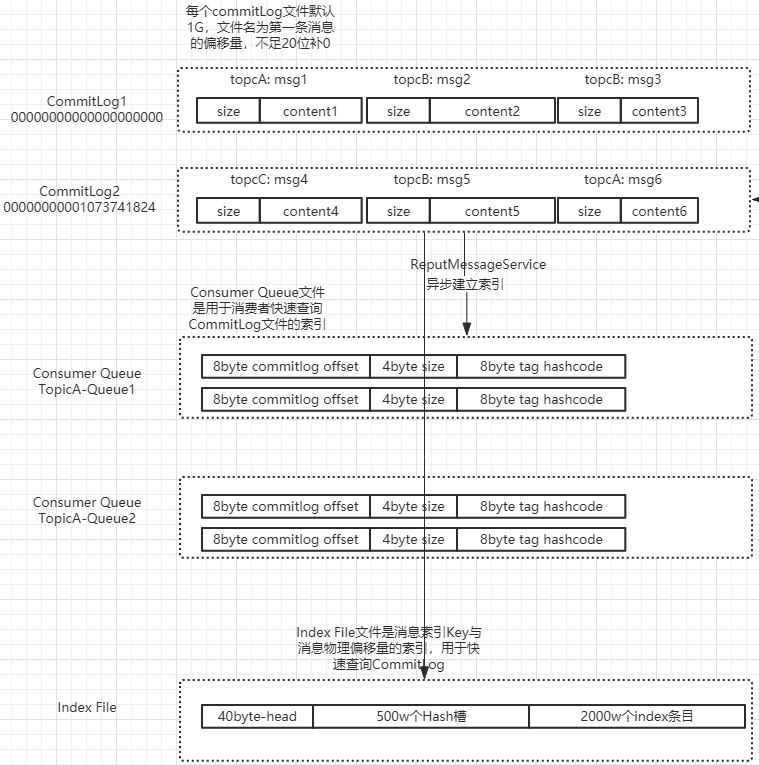
1.1 commitLog (类似Mysql的redolog)
消息存放的物理文件,是消息主体以及元数据存储的主体。每个broker上的 CommitLog被本机所有的Consumequeue共享,用于存储Producer端写入的消息主体内容,消息内容不是定长的,文件顺序写,随机读。单个文件大小默认1G 可以配置,文件名长度为20位,左边补零,剩余为起始偏移量,比如00000000000000000000代表了第一个文件,起始偏移量为0,文件大小为1G=1073741824;当第一个文件写满了,第二个文件为00000000001073741824,起始偏移量为1073741824,以此类推。消息主要是顺序写入日志文件,当文件满了,写入下一个文件。
commitlog存储单元结构图

1.2 ConsumeQueue
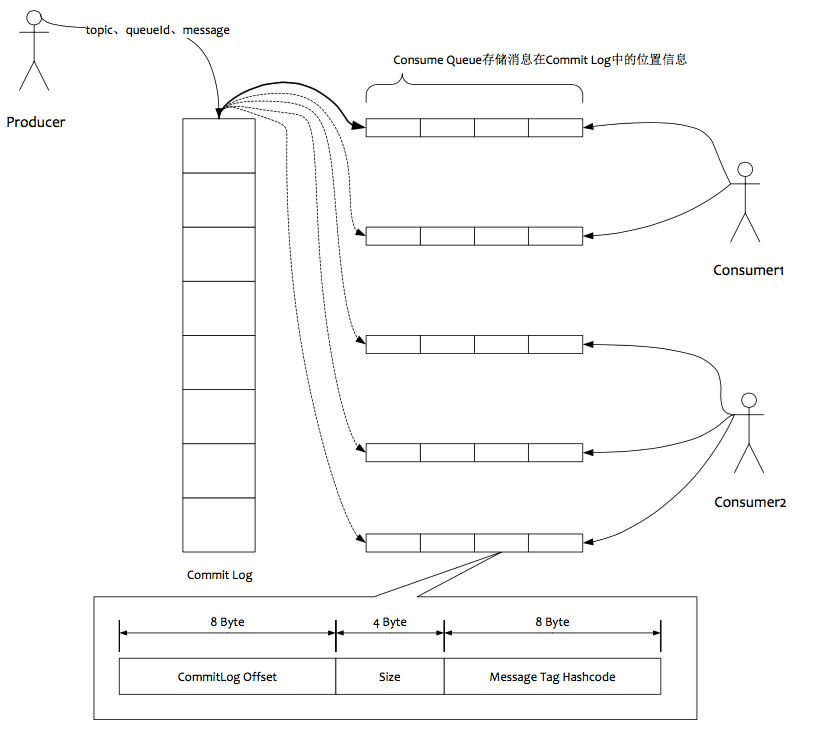
消息消费队列,引入的目的主要是提高消息消费的性能,由于RocketMQ是基于主题topic的订阅模式,消息消费是针对主题进行的,如果要遍历commitlog文件中根据topic检索消息是非常低效的。Consumer即可根据ConsumeQueue来查找待消费的消息。其中,ConsumeQueue(逻辑消费队列)作为消费消息的索引,保存了指定Topic下的队列消息在CommitLog中的起始物理偏移量offset,消息大小size和消息Tag的HashCode值。consumequeue文件可以看成是基于topic的commitlog索引文件,故consumequeue文件夹的组织方式如下:topic/queue/file三层组织结构,具体存储路径为:$HOME/store/consumequeue/{topic}/{queueId}/{fileName}。同样consumequeue文件采取定长设计,每一个条目共20个字节,分别为8字节的commitlog物理偏移量、4字节的消息长度、8字节tag hashcode,单个文件由30W个条目组成,可以像数组一样随机访问每一个条目,每个ConsumeQueue文件大小约5.72M;
consumerQueue 存储单元格结构
1.3 IndexFile
消息索引文件,Index 索引文件提供了对 CommitLog 进行数据检索,提供通过 key 或者时间区间来查询 CommitLog 中的消息的方法。在实际的物理存储上,文件名则是以创建时的时间戳命名的,固定的单个IndexFile文件大小约为400M,一个IndexFile可以保存 2000W个索引
IndexFile结构分析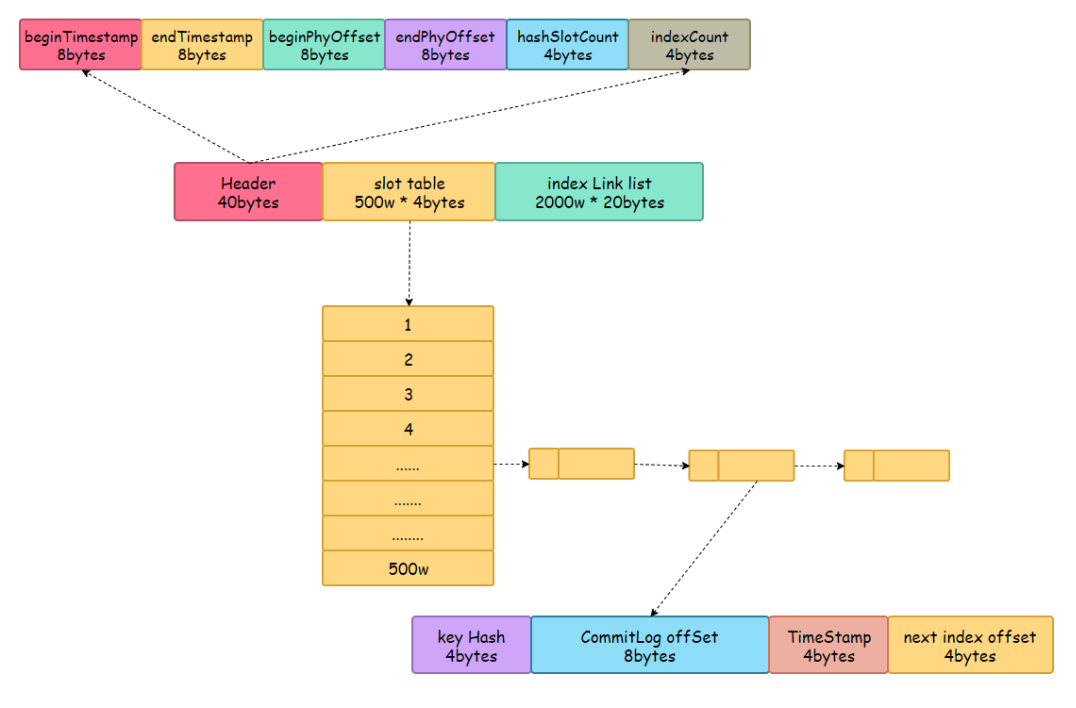
IndexHead:
- beginTimestamp:该索引文件包含消息的最小存储时间
- endTimestamp:该索引文件包含消息的最大存储时间
- beginPhyoffset:该索引文件中包含消息的最小物理偏移量(commitlog 文件偏移量)
- endPhyoffset:该索引文件中包含消息的最大物理偏移量(commitlog 文件偏移量)
- hashSlotCount:hashslot个数,并不是 hash 槽使用的个数,在这里意义不大,
- indexCount:已使用的 Index 条目个数
Hash 槽:
- 一个 IndexFile 默认包含 500W 个 Hash 槽,每个 Hash 槽存储的是落在该 Hash 槽的 hashcode 最新的 Index 的索引
Index 条目列表:
- hashcode:key 的 hashcode
- phyoffset:消息对应的物理偏移量
- timedif:该消息存储时间与第一条消息的时间戳的差值,小于 0 表示该消息无效
- preIndexNo:该条目的前一条记录的 Index 索引,hash 冲突时,根据该值构建链表结构
1.5 消息发送到消息消费数据流转
- Producer 将消息发送到 Broker 后,Broker 会采用同步或者异步的方式把消息写入到 CommitLog。RocketMQ 所有的消息都会存放在 CommitLog 中,为了保证消息存储不发生混乱,对 CommitLog 写之前会加锁,同时也可以使得消息能够被顺序写入到 CommitLog,只要消息被持久化到磁盘文件 CommitLog,那么就可以保证 Producer 发送的消息不会丢失

- CommitLog 持久化后,会把里面的消息 Dispatch 到对应的 Consume Queue 上,Consume Queue 相当于 Kafka 中的 Partition,是一个逻辑队列,存储了这个 Queue 在 CommitLog 中的起始 Offset,log 大小和 MessageTag 的 hashCode
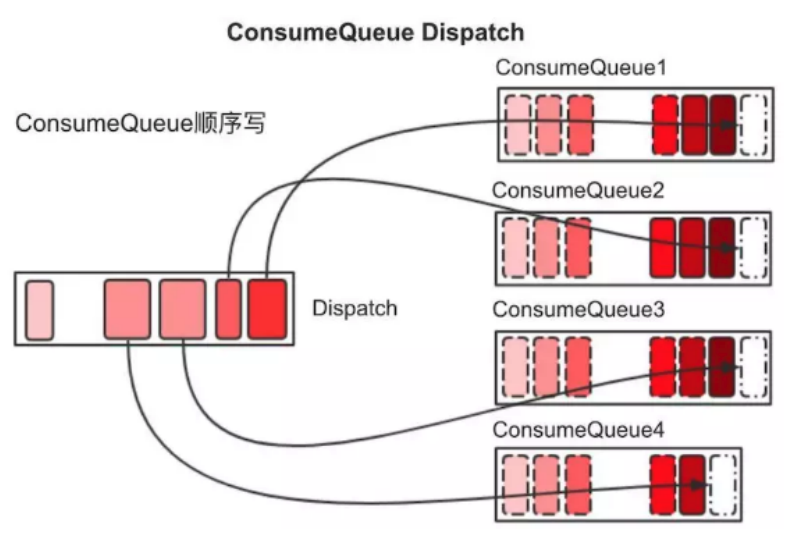
- 当消费者进行消息消费时,会先读取 ConsumerQueue,逻辑消费队列 ConsumeQueue 保存了指定 Topic 下的队列消息在 CommitLog 中的起始物理偏移量 Offset,消息大小、和消息 Tag 的 HashCode 值。
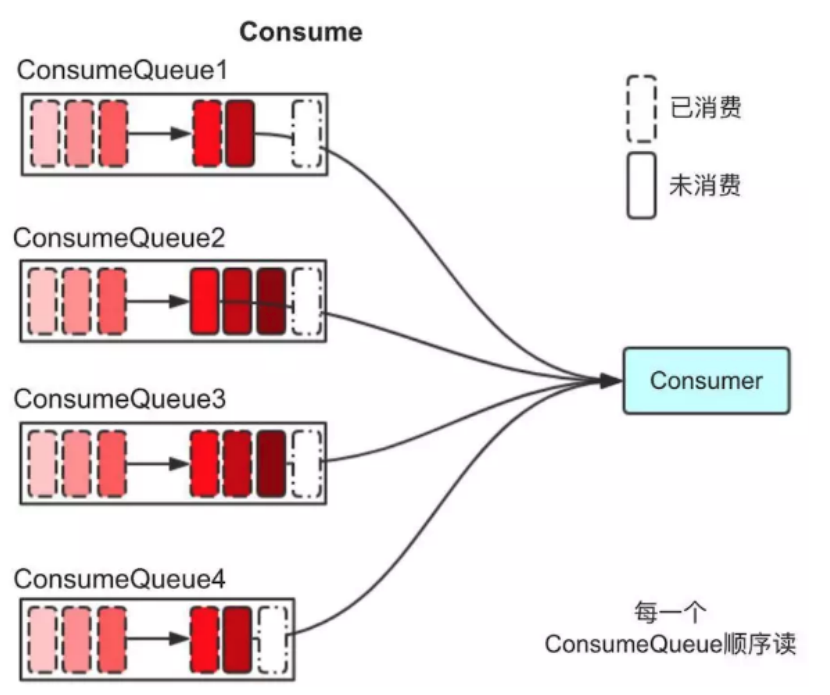
- 直接从 ConsumerQueue 中读取消息是没有数据的,真正的消息主体在 CommitLog 中,所以还需要从 CommitLog 中读取消息。

1.6 消息存储流程代码流程

- Broker端收到消息后,将消息原始信息保存在CommitLog文件对应的MappedFile中,然后异步刷新到磁盘
- ReputMessageServie线程异步的将CommitLog中MappedFile中的消息保存到ConsumerQueue和IndexFile中
- ConsumerQueue和IndexFile只是原始文件的索引信息
2 同步刷盘和异步刷盘
刷盘流程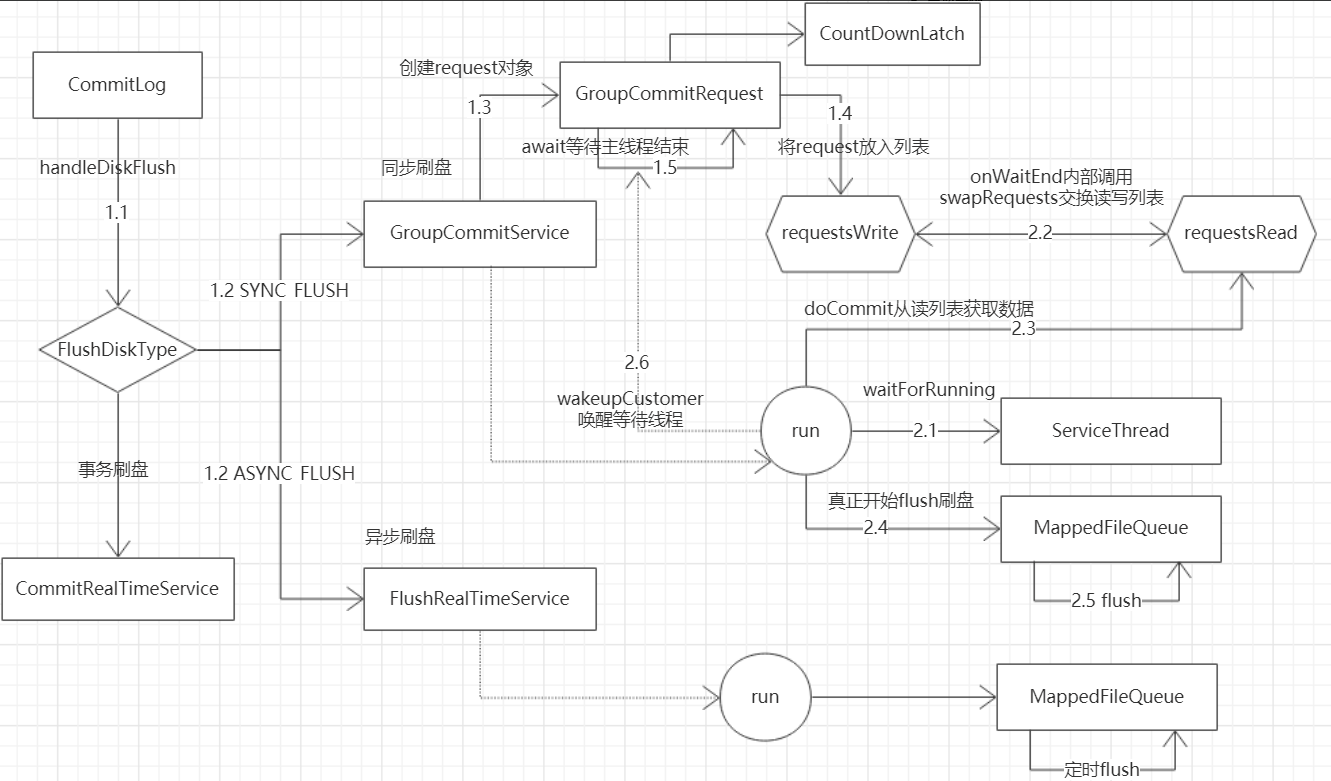
- producer发送给broker的消息保存在MappedFile中,然后通过刷盘机制同步到磁盘中
- 刷盘分为同步刷盘和异步刷盘
- 异步刷盘后台线程按一定时间间隔执行
- 同步刷盘也是生产者-消费者模型。broker保存消息到MappedFile后,创建GroupCommitRequest请求放入列表,并阻塞等待。后台线程从列表中获取请求并刷新磁盘,成功刷盘后通知等待线程。
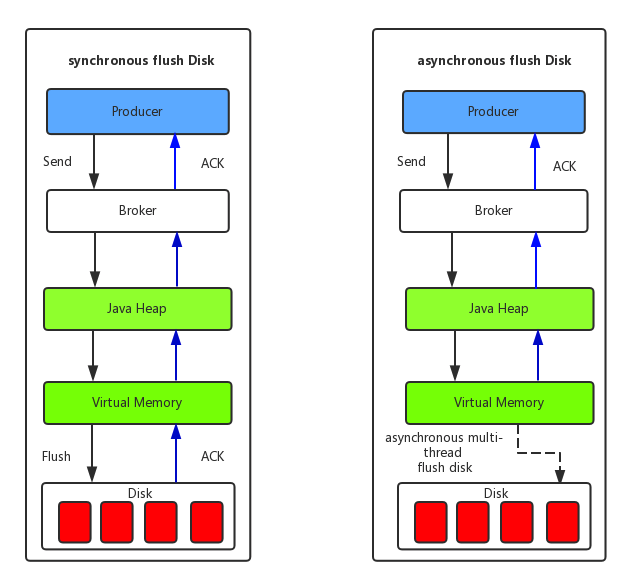
(1) 同步刷盘:如上图所示,只有在消息真正持久化至磁盘后RocketMQ的Broker端才会真正返回给Producer端一个成功的ACK响应。同步刷盘对MQ消息可靠性来说是一种不错的保障,但是性能上会有较大影响,一般适用于金融业务应用该模式较多。
(2) 异步刷盘:能够充分利用OS的PageCache的优势,只要消息写入PageCache即可将成功的ACK返回给Producer端。消息刷盘采用后台异步线程提交的方式进行,降低了读写延迟,提高了MQ的性能和吞吐量。
读取消息的ConsumeQueue文件也会加载到PageCache,读PageCache和内存速度差不多。
2.1 刷盘方法调用流程
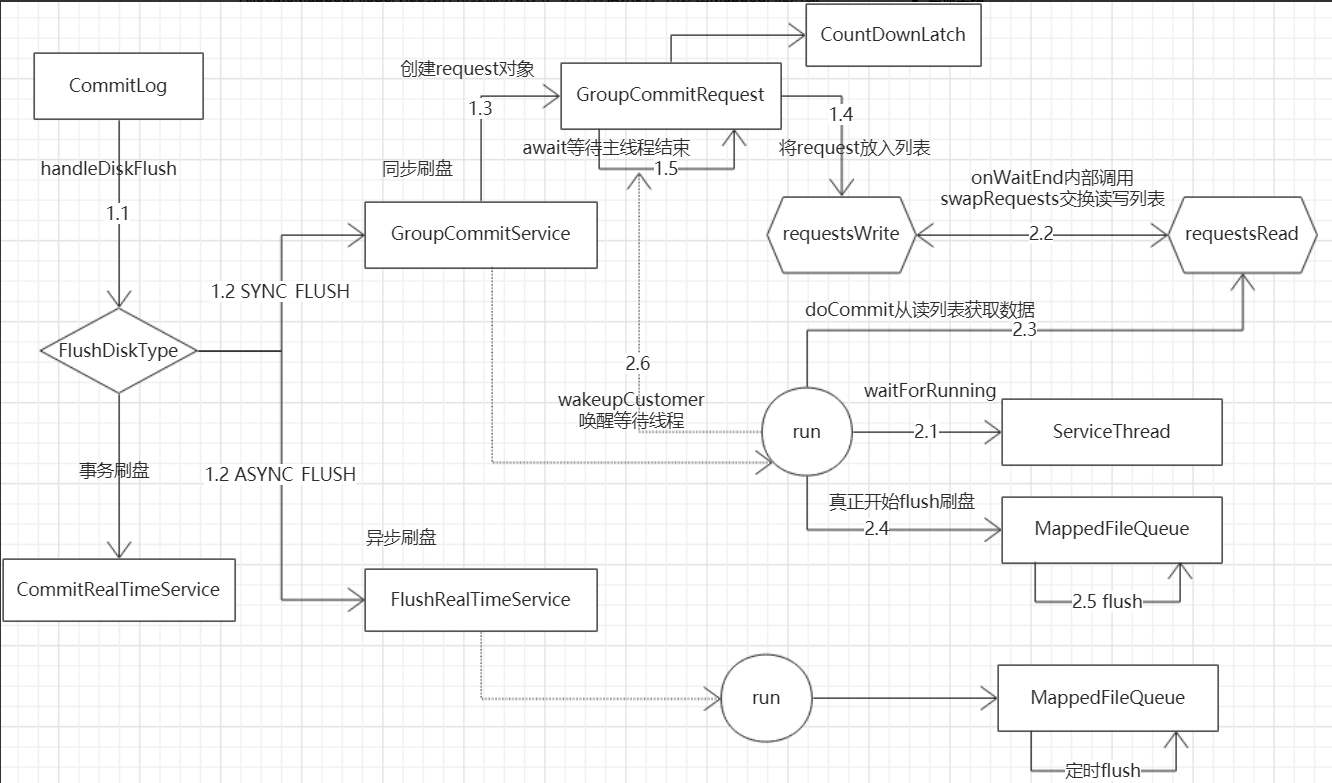
- producer发送给broker的消息保存在MappedFile中,然后通过刷盘机制同步到磁盘中
- 刷盘分为同步刷盘和异步刷盘
- 异步刷盘后台线程按一定时间间隔执行
- 同步刷盘也是生产者-消费者模型。broker保存消息到MappedFile后,创建GroupCommitRequest请求放入列表,并阻塞等待。后台线程从列表中获取请求并刷新磁盘,成功刷盘后通知等待线程
3 同步复制和异步复制
3.1 异步复制
消息写到 Broker 后,直接返回客户端成功,消息数据异步到 Slave 节点
优点:性能高,不需要等到消息同步直接返回。适合能容忍消息丢失的场景
缺点:这种可能会导致消息丢失
3.2 同步复制
消息写到Broker 后,需要将消息同步复制到 Slave 节点才返回成功
优点:能够保证消息绝对不丢失,保证高可用,这种适合和金融相关的业务
缺点:性能不高,因为需要将消息同步到 slave 才能能返回成功
4 高可用机制
4.1 Broker 集群
| 名称 | 描述 | 优点 | 缺点 |
|---|---|---|---|
| 单个 Master | 这种方式风险较大,一旦Broker 重启或者宕机时,会导致整个服务不可用,不建议线上环境使用 | ~ | ~ |
| 多 Master 模式 | 一个集群无 Slave,全是 Master,例如 2 个 Master 或者 3 个 Master, 消息分别写到不同的 master 节点上 | 配置简单,单个Master 宕机或重启维护对应用无影响,在磁盘配置为 RAID10 时,即使机器宕机不可恢复情况下,由与 RAID10 磁盘非常可靠,消息也不会丢(异步刷盘丢失少量消息,同步刷盘一条不丢)。性能最高 | 单台机器宕机期间,这台机器上未被消费的消息在机器恢复之前不可订阅,消息实时性收到影响 |
| 多 Master 多 Slave 模式,异步复制 | 每个 Master 配置一个 Slave,有多对Master-Slave,HA 采用异步复制方式,主备有短暂消息延迟,毫秒级。消息写入 Master 节点,异步复制到 Slave节点 | 即使磁盘损坏,消息丢失的非常少,且消息实时性不会受影响,因为 Master 宕机后,消费者仍然可以从 Slave 消费,此过程对应用透明。不需要人工干预。性能同多 Master 模式几乎一样 | Master 宕机,磁盘损坏情况,会丢失少量消息 |
| 多 Master 多 Slave 模式,同步双写 | 每个 Master 配置一个 Slave,有多对Master-Slave,HA 采用同步双写方式,master和slave都写成功,向应用返回成功。 | 数据与服务都无单点,Master宕机情况下,消息无延迟,服务可用性与数据可用性都非常高 | 性能比异步复制模式略低,大约低 10%左右,发送单个消息的 RT 会略高。目前主宕机后,备机不能自动切换为主机,后续会支持自动切换功能。 |
4.2 Dledger
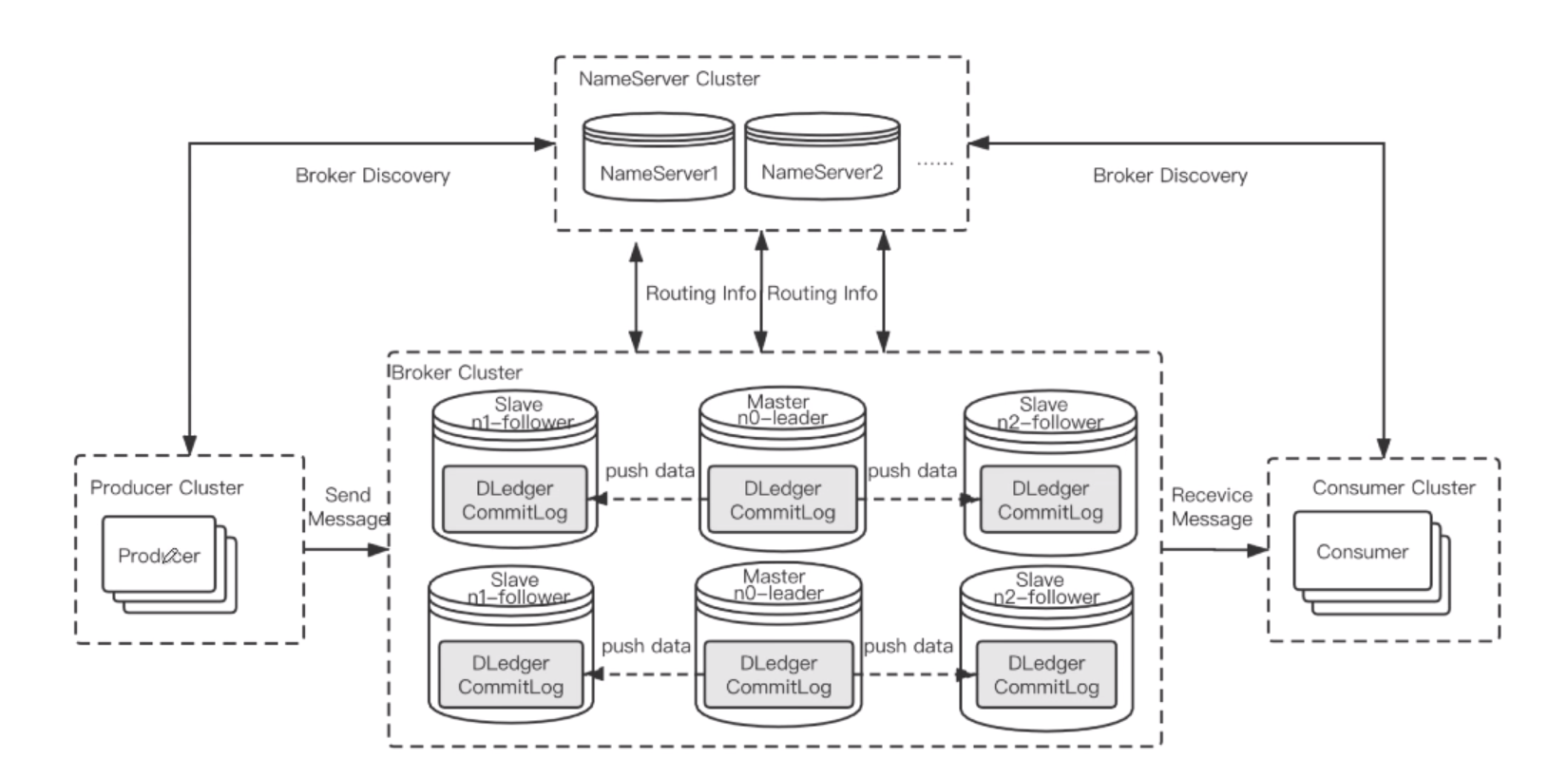
支持故障转移,自动将 slave 节点提升为 master 提供服务